
Tweet, like and share – das soziale Netzwerk mit dem charakteristischen blauen Vogel bietet heute über 211 Millionen aktiven Nutzern täglich und allgemein einem jedem die Möglichkeit, sich mit Menschen aus aller Welt über die unterschiedlichsten Themenbereiche von Politik und Wissenschaft über Sportevents und Trends hin zu alltäglichen Situationen aus dem privaten Alltag auszutauschen. Dabei stehen angemeldeten Nutzern je Tweet (dt. Gezwitscher oder Piepsen) maximal 280 Zeichen zur Verfügung, um Gedanken und Emotionen auf dem sozialen Netzwerk zu teilen. Zahlen wie etwa 350.000 Tweets jede Minute, 500 Millionen Tweets täglich und 200 Milliarden Tweets im Jahr (Ahlgren 2022) unterstreichen die (noch immer steigende) Beliebtheit des sozialen Netzwerkes zusätzlich.
In einem Anwendungsbeispiel sammeln Prof. Dr. Christoph Laroque und sein Forschungsteam seit Juli 2020 die steigende Datenmenge rund um den Suchbegriff „Big Data“ und den dazugehörenden Hashtag #BigData. Hierfür ist neben einem Python-Skript (im ersten Teil) genauso ein einfacher Workflow mittels der freien Software für interaktive Datenanalyse KNIME (im zweiten Teil) im Rahmen einer kleinen Betragsreihe bestehend aus drei Beiträgen vorgestellt und erläutert worden.
Im Folgenden sollen schließlich in einem dritten und letzen Teil dieser Beitragsreihe ein automatisierter Workflow gemäß einer Zusammenführung und Weiterverarbeitung der einzelnen Abfragen (Abbildung 1) und eine Visualisierung der Datenmenge rund um den Suchbegriff „Big Data“ und den dazugehörenden Hashtag #BigData unter Verwendung der Datenvisualisierungssoftware Tableau und der 3D-Visualisierungssoftware Unity3D beschrieben werden.

Während die Erhebung und Sammlung von Tweets identisch zu dem in Teil 2 dieser Beitragsreihe gezeigten (einfachen) Workflow funktioniert, werden in dem hier dargestellten Workflow alle nachfolgenden Schritte im Hinblick auf eine Auswertung verwendeter Hashtags abseits von #BigData und eine Aufbereitung von Teilen der Gesamtabfrage für die Visualisierung in einer virtuellen Umgebung als Teil des virtuellen Forschungslabors1 automatisiert. Entsprechend sind die Komponenten Table Writer und Table Reader ein wesentlicher Bestandteil des Workflows, um die aufkommenden Datenmengen einer aktuellen Abfrage in die Gesamtabfrage zu übernehmen und die Gesamtabfrage folgend zu sichern. Die Komponenten Generic Loop Start und Variable Condition Loop End definieren dabei eine Endlosschleife. Die Abfrage neuer Tweets erfolgt in einem Zeitintervall von 12 Stunden und folgend zweimal täglich. Dieses Zeitintervall kann bei Bedarf angepasst werden.
Ein neuerliches Einlesen der Datenmengen nach jeder neuen Abfrage sichert danach die Vollständigkeit und Aktualität der Twitter-Daten für die weitere Verarbeitung ab. Die Komponente Tableau Writer ist für das Schreiben der Gesamtabfrage als Tableau-Extraktdatei (.hyper) verantwortlich und garantiert ein Einlesen in einer und ein Aktualisieren einer Tableau-Arbeitsmappendatei innerhalb weniger Momente. Ein Einlesen und Aktualisieren einer Tableau-Arbeitsmappendatei über eine Excel-Datei kann dagegen sehr zeitaufwendig2 sein.
Auswertung verwendeter Hashtags und Visualisierung in Tableau
Für die Auswertung verwendeter Hashtags abseits von #BigData ist schließlich die ähnlich benannte Prozesskette (Abbildung 2) verantwortlich. Im Wesentlichen werden die Tweets entsprechend einer RegEx-Anweisung #\w+ in der Komponente Table Creator und die darauffolgenden Komponenten Wildcard Tagger und Tag Filter analysiert. Im Ergebnis dieser Prozessschritte sind in der Komponente Bag Of Words Creator die resultierenden Hashtags zusammen mit dem festgelegten Tag Type (hier SENTIMENT) und Tag (hier AMPLIFICATION) in der Spalte Term ausgewiesen. In der Folge wird die Abfrage entsprechend der Komponente GroupBy und einer Anzahl der Vorkommen verwendeter Hashtags (Count) für die aktuelle Abfrage in der Spalte Term gruppiert und nachfolgend durch die Komponente Sorter gemäß dieser Anzahl absteigend sortiert.
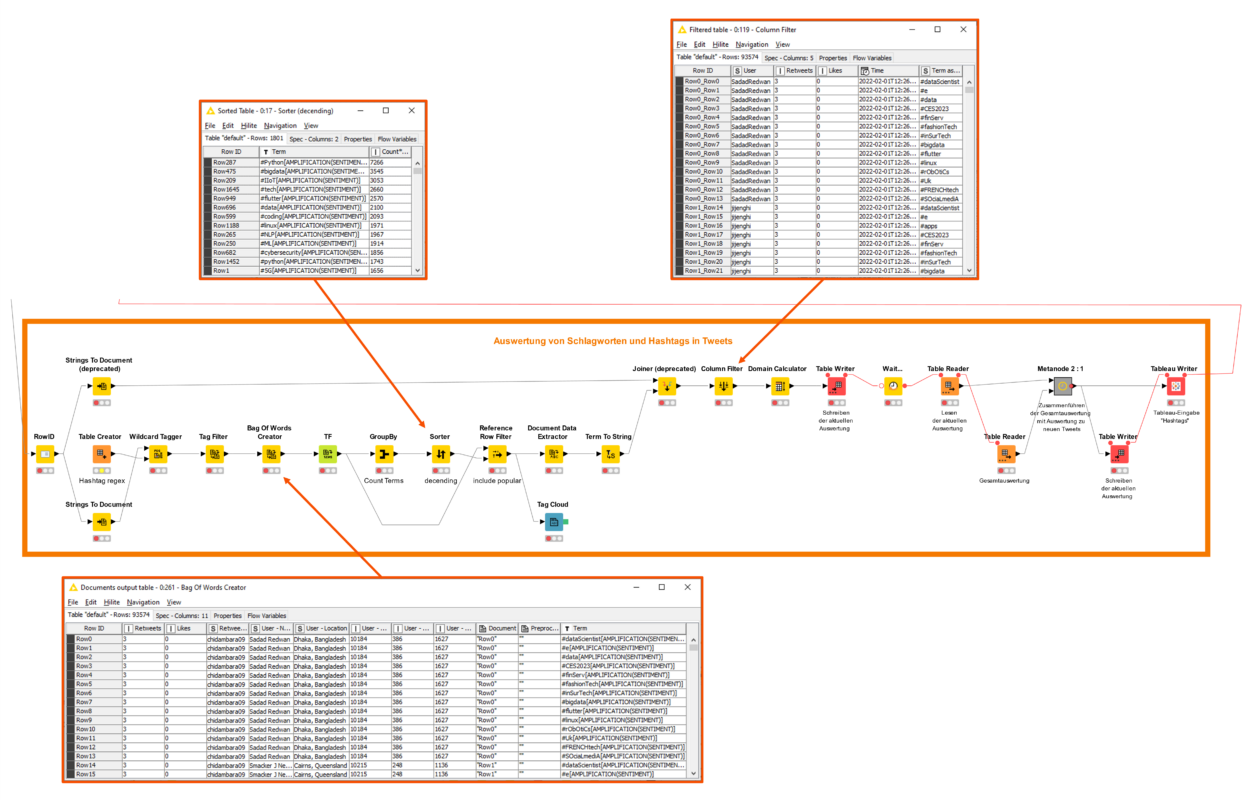
Nach einer weiteren Verarbeitung in den Komponenten Reference Row Filter, Document Data Extractor und Term To String werden die resultierenden Tabellen über die Komponente Joiner zusammengeführt. Die Komponente Column Filter beschränkt die Tabelle dabei auf die Spalten User, Retweets, Likes, Time und Term as String. Diese Spalten sollen dafür Sorge tragen, dass die Gesamtabfrage und die dazugehörende Visualisierung in der Datenvisualisierungssoftware Tableau Diagramm-übergreifend gemäß bestimmter Informationen (bspw. User) gefiltert werden kann. Im letzten Schritt sind die Komponenten Table Writer und Table Reader dafür verantwortlich, die aufbereitete Abfrage in die Gesamtabfrage zu übernehmen und zu sichern. Die Komponente Tableau Writer schreibt die Gesamtabfrage für die Auswertung verwendeter Hashtags zusätzlich als Tableau-Extraktdatei (.hyper).
Eine Visualisierung der anfallenden Datenmenge rund um den Suchbegriff „Big Data“ und den dazugehörenden Hashtag #BigData unter Verwendung der Datenvisualisierungssoftware Tableau umfasst nachstehend (nahezu) alle Tweets im Zeitraum vom 10. Juli 2020 bis zum 01. Februar 2022 (Abbildung 3). Über diesen Zeitraum liegen dabei etwa 11 Millionen Tweets rund um den Suchbegriff „Big Data“ und den Hashtag #BigData vor, während die Auswertung verwendeter Hashtags über 40 Millionen Einträge beziehungsweise Vorkommen zählt.

Visualisierung der Datenmenge in einer virtuellen Umgebung
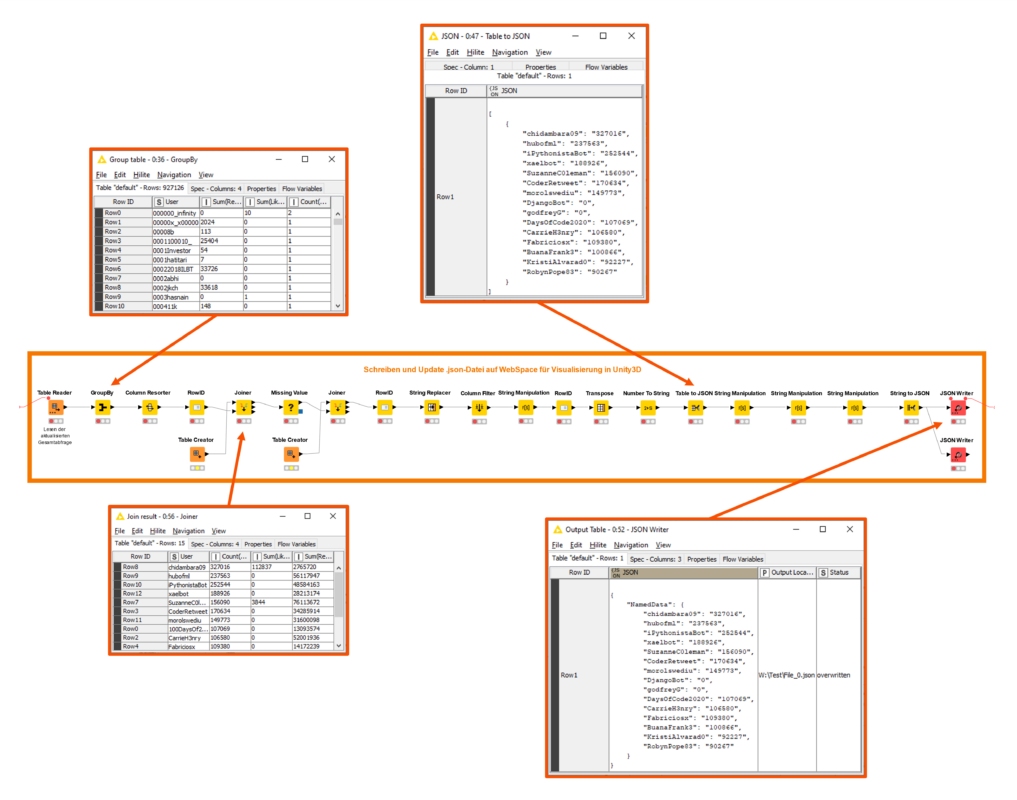
Für die Visualisierung eines Teils der Datenmenge in einer virtuellen Umgebung als Teil des virtuellen Forschungslabors1 ist dann die ähnlich benannte zweite Prozesskette (Abbildung 4) verantwortlich. Die Komponente Table Reader ist dabei zunächst für das neuerliche Einlesen der aktualisierten Gesamtabfrage verantwortlich. Die Datenmenge wird folgend einer Anzahl der Vorkommen eines Anzeigenamens in der Spalte User unter Verwendung der Komponente GroupBy gruppiert und in weiteren Prozessschritten für die Visualisierung in der 3D-Visualisierungssoftware Unity3D aufbereitet. Der resultierende Datenauszug wird schließlich in der Komponente Table To JSON in das entsprechende Textformat übertragen und im Anschluss gemäß einer notwendigen Detaillierung von Seiten des Unity3D-Assets und dazugehörenden C#-Skripts angepasst und als .json-Datei auf einem WebSpace gespeichert. Die Speicherung auf einem WebSpace ermöglicht dabei, die Datenmenge automatisch in der virtuellen Umgebung (erneut über ein C#-Skript) zu aktualisieren.
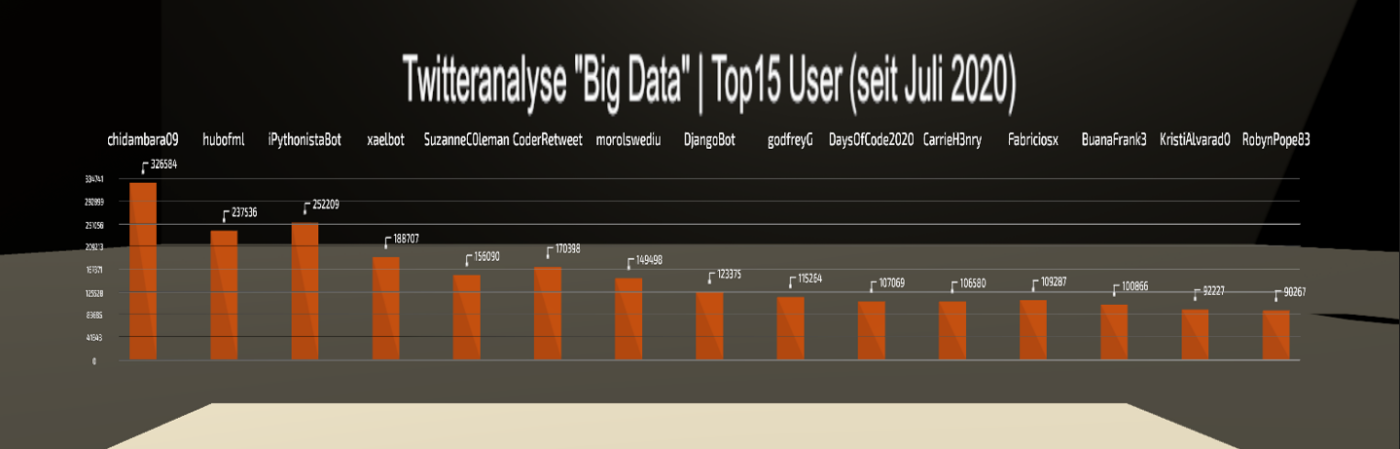
Eine Visualisierung der anfallenden Datenmenge rund um den Suchbegriff „Big Data“ und den dazugehörenden Hashtag #BigData unter Verwendung der 3D-Datenvisualisierungssoftware Unity3D zeigt nachstehend das Vorkommen gemäß einer Anzahl Tweets von fünfzehn der aktivsten Nutzer3 im Zeitraum vom 10. Juli 2020 bis zum 01. Februar 2022 (Abbildung 5).
1 Das virtuelle Forschungslabor kann in limitierter Form als WebGL-Anwendung über einen anderen Beitrag hier aufgerufen werden. Für die WebGL-Anwendung steht die hier beschriebene Datenvisualisierung im Moment jedoch noch nicht zur Verfügung (Stand Februar 2022).
2 Im hier beschriebenen Anwendungsbeispiel teilweise über eine Stunde.
3 Zum Zeitpunkt einer früheren Abfrage handelte es sich hier um die Top15 der aktivsten Nutzer.