
Tweet, like and share – das soziale Netzwerk mit dem charakteristischen blauen Vogel bietet heute über 211 Millionen aktiven Nutzern täglich und allgemein einem jedem die Möglichkeit, sich mit Menschen aus aller Welt über die unterschiedlichsten Themenbereiche von Politik und Wissenschaft über Sportevents und Trends hin zu alltäglichen Situationen aus dem privaten Alltag auszutauschen. Dabei stehen angemeldeten Nutzern je Tweet (dt. Gezwitscher oder Piepsen) maximal 280 Zeichen zur Verfügung, um Gedanken und Emotionen auf dem sozialen Netzwerk zu teilen. Zahlen wie etwa 350.000 Tweets jede Minute, 500 Millionen Tweets täglich und 200 Milliarden Tweets im Jahr (Ahlgren 2022) unterstreichen die (noch immer steigende) Beliebtheit des sozialen Netzwerkes zusätzlich.
In einem Anwendungsbeispiel sammeln Prof. Dr. Christoph Laroque und sein Forschungsteam seit Juli 2020 die steigende Datenmenge rund um den Suchbegriff „Big Data“ und den dazugehörenden Hashtag #BigData. Hierzu ist in einem ersten Teil einer kleinen Beitragsreihe bestehend aus drei Beiträgen ein Python-Skript für die Erhebung und Sammlung von Tweets für eine konkrete Suchabfrage vorgestellt und erläutert worden (Abbildung 1).

Im Folgenden soll nun in einem zweiten Teil dieser Beitragsreihe die Erhebung und Sammlung von Tweets über die freie Software für interaktive Datenanalyse KNIME („Konstanz Information Miner“) anhand eines einfachen Workflows beschrieben werden, welche sich für den Anwendungsfall und die nachfolgende Visualisierung der Datenmenge rund um den Suchbegriff „Big Data“ und den dazugehörenden Hashtag #BigData bewähren konnte.
Für die Erhebung und Sammlung von Tweets ist ein Workflow, eine Art Graph bestehend aus mehreren Komponenten (auch Knoten, engl. Nodes), entwickelt worden, um Tag für Tag alle Tweets hinsichtlich des Suchbegriff „Big Data“ und den dazugehörenden Hashtag #BigData abzufragen, entsprechend zu filtern und schließlich in eine Excel-Datei schreiben zu lassen (Abbildung 2). Die Authentifizierung erfolgt dabei über die Komponente Twitter API Connector und basiert auf erneut auf den Identifikationsschlüsseln, die sich über ein Entwicklerkonto bei Twitter und die Erstellung einer Applikation generieren lassen.

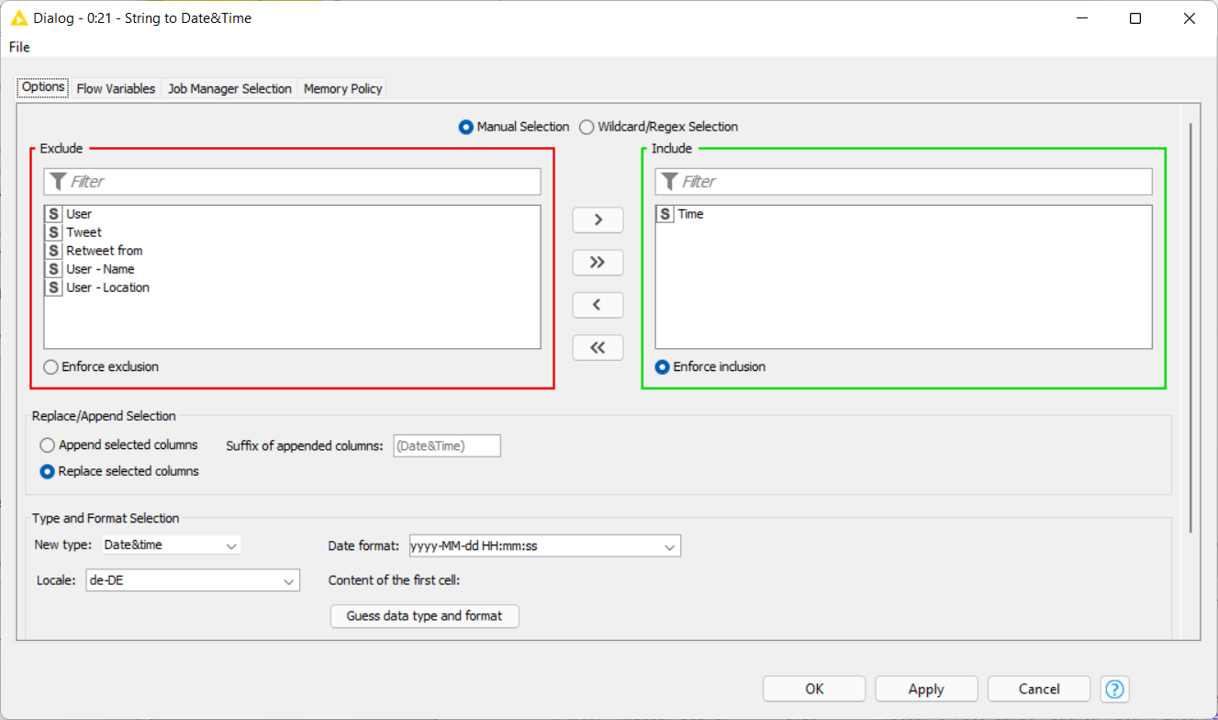
Hinter den Komponenten (bspw. Twitter API Connector oder String to Date&Time) stecken demnach verschiedene Prozessschritte. Diese Prozessschritte sind zu großen Teilen vordefiniert und müssen lediglich konfiguriert werden (Abbildung 3). Demgegenüber besteht zeitgleich die Möglichkeit auf echten Code zurückzugreifen. Hierzu werden unzählige Erweiterungen (KNIME Extensions) angeboten, die es ermöglichen die Workflows nach Belieben zu erweitern und den konkreten Anwendungsfällen entsprechend anzupassen.
Die wesentliche Abfrage der Tweets erfolgt schließlich über die Komponente Twitter Search und einer Suchabfrage „Big Data“ OR #bigdata. Die abgefragten Tweets enthalten folglich entweder das den Suchbegriff „Big Data“ im Wortlauf oder den dazugehörenden Hashtag #BigData. Eine Erweiterung der Suchabfrage um den Operator until:2022-01-23 (Jahr-Monat-Tag) wäre, beispielsweise, dafür zu verwenden, um die Tweets für den 22. Januar 2022 abzufragen, während die Suchabfrage ohne diesen Operator stets die aktuellen Tweets bis zu dem Zeitpunkt der Abfrage enthält. Eine Auflistung aller Suchoperatoren für eine Abfrage auf Twitter ist hier zu finden.
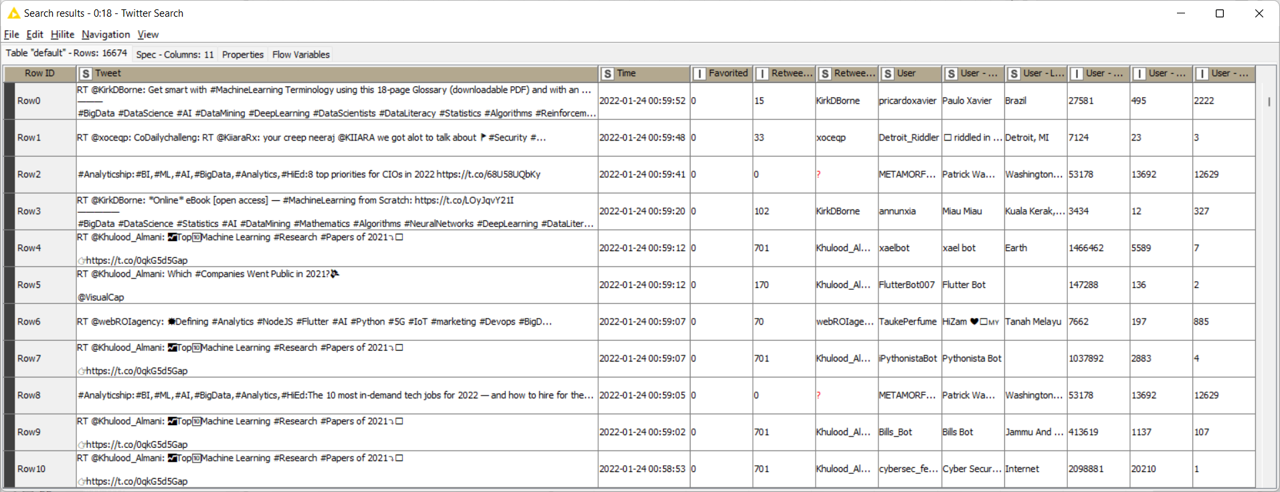
Die resultierende Abfrage (Abbildung 4) enthält in diesem Fall den Tweet, das Datum, die Anzahl der Likes (Favorited) und Retweets, den Name und den Anzeigename (Username) des Nutzers sowie Informationen über dessen Herkunft (durch freie Angabe mitunter sehr ungenau), die Anzahl der Tweets und Follower. Diese Abfrage kann dann je nach Bedarf einer Reihe von Prozessschritten unterzogen werden. Entsprechend sind in diesem Fall die Spalten umsortiert und namentlich angepasst worden, bevor die Komponente String to Date&Time das Datumsformat für die weitere Verarbeitung anpasst und die Abfrage schließlich über die Komponente Excel Sheet Appender (XLS) einer Excel-Datei hinzugefügt wird.
Im dritten und letzten Teil dieser Beitragsreihe soll schließlich ein automatisierter Workflow gemäß einer Erhebung, Zusammenführung und Weiterverarbeitung einzelner Abfragen und eine Visualisierung der Datenmenge rund um den Suchbegriff „Big Data“ und den dazugehörenden Hashtag #Big Data unter Verwendung der Datenvisualisierungssoftware Tableau und der 3D-Visualisierungssoftware Unity3D vorgestellt werden.